



Looking back at PKM Summit 2025
or: being data-centric in a tool-centric world

PKM Summit 2025 in Utrecht was a blast - SEN, my semantic desktop dream, hit the stage for the 2nd time. It’s local and private, but on demand also global and connected, and lets you build simple custom applications. Read on for an overview and some insights into what made people excited - and stay tuned for the slides and a video recording of the talk!
Short Intro on PKM Summit 2025
PKM Summit 2025 was a blast, vibing with my tribe, getting a lot of positive feedback and meeting extraordinary nice and knowledgeable people, having fun and being nerdy - refreshing, exhausting (including late-night coding to get my demo finished…) and inspiring. Ticket for 2026 is already booked. There are and will be much better write-ups about the conference, so let me just focus on why you are here: SEN :)
I have been given the wonderful opportunity to present my project SEN again this year, this time with a prototype under my arms, and a nice friend helped me with setup and recording a video of the presentation.

Being a professional software developer (with over 20 years of industry experience in different settings, sizes, environments and domains) and mingling with non-developers from various domains, using tools to actually get things done ;-) is always a refreshing reality check.
This keeps me grounded and brings me back into a healthy balance between my vision, aims and curiosity, playing with cool and nerdy stuff, and some real world use cases and needs by actual people that want to use software for professional needs.
Mingling with mortals (just for the pun;-) also shows some insights and potential misconceptions that I strive to correct or at least uncover, in this case: the never-ending fetishization of tools and methods at the expense of interoperability and flexibility.
Nicole van der Hoeven also pointed this out in the closing panel discussion, and I couldn’t agree more.
The (current) Tool-Centric Approach
The love for Tool X (let’s call it Obsidian) reminds me of the age-old debates in software engineering, with heated discussions over what editor to use, Emacs or vim (I love nano;-), or now Atom/Zed vs. VScode vs…
The file/document format issue was fortunately settled early in software engineering, concluding that TEXT was a universal format that could be enriched as needed but still be readable and writable in any tool. This is also why versioning and merging changes between developers of all kind works so well. It does not matter if you work on Mac, Windows (now that it finally supports Unicode…) or Linux. Neither your editor of choice makes any difference. In the end, it’s all text.
That revelation has also made it into the knowledge management world with the discovery that a (mostly Markdown based) text files-approach is the most flexible and open solution to manage notes. This was also made popular by Obsidian’s “file over app” approach - but this is only “half the rent”, as we say in Austria, meaning it’s only half way through towards the finish line of a real solution. To put it more bluntly, it’s not enough to really call it an open solution, and here is why:
All your precious notes may be stored as text (using Markdown and some magic metadata), but they are still bound to a specific tool: mixing metadata with the actual data is never a really good idea, and all the less if it contains SQL like queries or “data views”. The format may be open, but the logic is strictly tool-centric and - even worse - you rely on external plugins that only work with the tool you currently favor.
Without the tool and its magic plugins, all your links and queries, reports and drawings will be useless and hard to export. The Tool still has control over your data, not you. All the work you put in to connect, label and organize your data is still bound to a specific tool, and you have to use plugins to make that tool work for every use case you need (drawing, writing, planning,…).
Just look at these cute little tools here - all keeping the information (not the text data) to themselves, never really sharing in a usable way, and leaving out the poor guy to the right:

Lastly, due to limits in current systems, these tools force you - at best - to keep all your data in TEXT format, but not all data is TEXT. In the excellent talk, PKM Across the Semantic Spectrum, on the PKM Summit 2025, Larry Swanson brought up an important core mantra of the semantic web, which also applies to the domain of Personal Knowledge Management:
Things, not Strings.
Initially coined by Google when introducing the first known enterprise knowledge graph, this means that you should add semantics to your data, not just keep everything as untyped, generic text. This makes search much more powerful and flexible, and keeps the meaning of the data that is valuable to you.
The Data-Centric Approach
Contrast this with a truly data-centric approach, which is a central design decision by SEN and its underlying OS, Haiku:
There is a common infrastructure that extracts, enriches and connects your data on your behalf, stores that metadata separately but still attached to your files in the filesystem.
Now, all this work has to be done only once and be accessible to the entire environment, including *all* your tools. You will never loose, it, since it’s stored as part of your files and any application can access the open metadata format (filesystem attributes, like key/value maps)
Now you have something like this:

Native File Types to Represent your Data
Now, consider a system that is not only data-centric but also natively supports semantic file types, so you can easily map objects of your domain directly into your PKM system, without complicated tool-specific type systems or plugins - just good old file types provided by the system, which you can even modify and adapt with the default filetypes system settings?
Files are not simple technical containers for documents or media files but can represent anything and have custom properties: not just text, but drawings, calendar events, all kinds of media, even abstract types like Books or Places. Even classification is done with files that act as placeholders and connect data you label with them. You can navigate relations right from the file browser, like from an Author to Books in your library:

Imagine managing your book notes as linked text notes which reference real Book files that have an ISBN attribute, subjects, genre, page count and publisher, and a link to its Author(s).?
Now imagine, going further, that you can freely search for these custom attributes, e.g. searching for Books of a certain genre, matching given subjects or directly check if you own a Book with a specific ISBN?
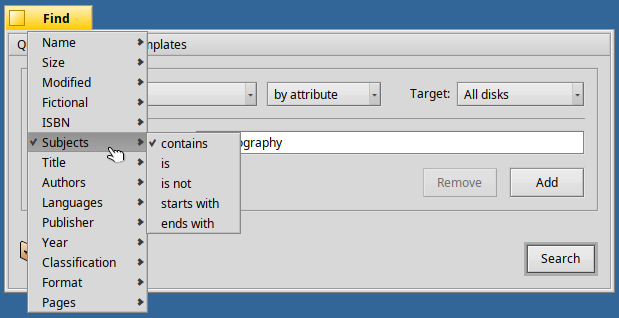
SEN is the first PKM system that supports all this right from the desktop, interacting with existing data and tools, but not locking you into any method, tool(set) or plugin-configuration. SEN is an infrastructure, not a tool, thus providing a horizontal, integrative and data-centric approach as opposed to a vertical, tool-centric approach with increasing complexity growing with every plugin you add. And even better, it supports automatic lookup of metadata, e.g. Book information from OpenLibrary.org (which is part of the Internet Archive).

Take your tools into the Future
No need to throw away your tool set, it’s hopefully just Markdown text files with some magic sprinkle dust to overcome limitations of outdated current systems and act as a bridge to something better: SEN with native support for Entities and Relations.
If there is enough interest and support, I will prioritize Markdown support in SEN, allowing you to navigate your relations right from the file browser, searching for notes based on metadata, and even perform the queries hidden in magic YAML Markdown metadata right from the system’s Find panel.
In the coming weeks and months, I will integrate support for other use cases like managing and navigating research papers via DOI or ISSN, or managing your local movie or music library. The wonderful thing of a data-centric and powerful but easy-to-use system like Haiku+SEN is that you can build your personal ontologies for your own needs and use them from within any tool, even just your everyday file browser, and navigate local linked data in your filesystem with SEN.
The coming summer will be the SOS - Summer Of SEN, where you will finally be able to try out a Tech Preview and get your hands dirty with the semantic desktop of the future.
If you are willing to try out an environment that is actually designed for knowledge work and which is simple, elegant and fun to use, performant and open source, then you are welcome to join the ride… who knows, maybe SEN would even run on your current OS at a later time, but first the vision needs to materialize on fertile ground…
How can I support SEN?
Glad you asked - the first and easiest would be to upgrade to a paid membership plan via this handy button:
(maybe even get a full-featured founders membership that will give you some perks like personal thanks in the About dialog or early builds for local testing…)
Then, the project is open source and I am building in public, so you can star and sponsor the project right from within Github:
That’s all for now, still need to rebuild myself after an intense time (preparation and the conference itself), stay tuned as the future of the semantic desktop for personal knowledge management unfolds!