



Getting SENtimental - a 2024 review
it was a wild ride already, and the journey is just beginning...


So at the last day of the year, it is time for a recap and a quick update on what happened with my passion project SEN in the meantime… considering the previous (first and only) blog post was in January, you could be deceived to think the project stalled, but quite the contrary…!
This is just a quick overview and write-up about my year with SEN, more detailed insights will follow as I work on the individual parts in the coming weeks and months. Please don’t hesitate to ask questions, give me feedback and - at this stage, most important - consider upgrading to a paid subscription to keep the SEN momentum going!
Getting Serious
After a slow start (recovering from a burnout that got me in the 2nd half of 2023), things got in full swing with my admission to the first summit on personal knowledge management, the PKM Summit 2024 in Utrecht that was held in last March.
Preparation for the talk got me really motivated to finally start coding, so after a successful and very inspiring 2 days in Utrecht (see below), I was really eager to start coding… this has sadly led to a lack of updates in the blog, only the occasional note made it through. I promise improvements on that matter in 2025 as a new year’s resolution.
With fresh energy and motivation, I was finally starting to make quite some progress on all components of SEN. I was focusing on various parts of the infrastructure in an agile manner, prototyping ideas, concepts and validating designs. I can now proudly say that the design holds and a tech preview is not far off.
Let’s look at some activity graphs from SEN Labs Github repository - yes, all components are now open source, but not final. Everthing is still heavily work-in-progress, but I decided to go all in and #buildinpublic (yes I’m also active on Bluesky now and enjoy the friendly and open, science-friendly geeky community there:-).
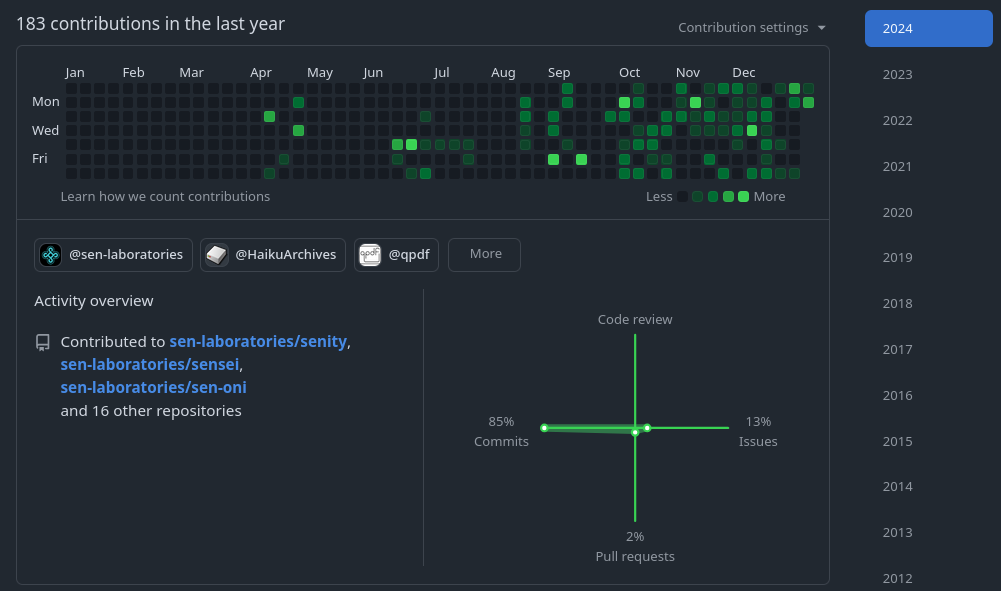
Looking at the code frequency graphs of individual SEN components prototyped so far and arranging them in a stacked manner, I can really provide an excuse for my lack of progress updates here - except for a much needed summer break, I was busy coding, not writing (see abovce):

The activity started in April, right after the conference in March. Spikes indicate my focus on various components of the SEN infrastructure, which can be summarized under the acronym SENSEI:
Structure-
Extraction,
Navigation,
Semantic
Enrichment and
Identification
I had some profound revelations during the prototyping phase (see “Re(ve)lations” section below) and adapted the technical design accordingly. Since I was moving fast, I could adapt quickly and did not have to care about compatibility, documentation, testing and all that other pesky stuff (that makes a usable product…;-).
I could also confirm that it was the right decision to build SEN on the foundation of Haiku, a very lightweight, fast, modern (filesystem wise but also considering various usability features that are still as innovative today as it was 25 years ago with Haiku’s origin, BeOS). While it is a niche OS, it provides everything needed to build a local, semantic desktop infrastructure for linked-data handling and personal knowledge management. Time, funding and your support will tell if I can ever port this to a more common OS, but for now I’m happy with Haiku, which is now almost ready for everyday use with the arrival of a promising IceWeasel port (basically Firefox sans telemetry).
Building in the Open
Recently, as mentioned above, I’ve gone all in (or rather out) and decided to release all code I am actively working on, which includes - as of yesterday - also the actual sauce which is sen-core, on the official SEN-Labs Github repository. This makes it easier to share code with the interested community for feedback or questions, e.g. when I’m not sure if it’s a bug in SEN or in Haiku, or a driver. It’s also more serious to put skin in the game and be completely transparent on the progress, which gives the project more credibility, hopefully, for funding and also makes some of you consider upgrading to a paid subscription… (my only paying subscriber was scared off by the lack of updates, so I really need your support now, every paid subscription counts!).
SEN at PKM Summit 2024
After a much needed hiatus in the second half of 2023, I kickstarted the year with going all out and speaking in public (for the first time:-). I took the chance and got the wonderful opportunity to speak at the first PKM summit in Europe, the PKM Summit 2024 in Utrecht, NL.
You can find the abstract in the archived timetable on the PKM website.
To put it short, the conference was a blast, lots of open, curious and friendly people. Conversations flowed naturally and reached from international small-talk (it was quite a mixed group) to deep and serious knowledge-management topics.
I am glad my presentation was well received (only some 25 people in a small room, but I was competing with - the - David Allen of GTD fame, so I’m happy:). It’s not a mainstream project, after all, and requires some unlearning and rewiring, but with great rewards…
Re(ve)lations
Revisiting SEN and starting implementation for real, I realized - much too late, but better late than never - something important about relations in SEN:
Previously, this was still a bit magic and I only had a concept of linking - like symbolic links, but SEN provides semantic links - using a separate configuration and the (message-based) SEN API to handle filesystem attributes for managing and resolving relations using native filesystem queries. I had not really thought this through all the way and was not looking forward to all the work needed to adapt the file browser Tracker as needed to support relations.
Turns out, I was again thinking too complicated, and the solution was so easy - since everthing on Haiku (in good old UNIX fashion) is a file with a MIME-based file type, why not make Relations also a special file type? This would automatically ensure Tracker displays them transparently, including relation properties in the details columns, like so:

This would have another nice side-effect: plugins to handle (and resolve) relations, including support for deep linking and target navigation (i.e. navigating to the relation target and doing highlighting or other useful actions for relation navigation, like jumping to a quotation in a referenced document) would be as easy as defining the plugin as default application for that relation file type!
Relation Configuration
To configure relations, users can resort to the standard Haiku FileTypes preferences like so (using the custom super type “relation”, which is just a convention and perfectly legal in this context):

A plugin is then just a simple native application (could even be a Python script with some wrapper code) that supports the relation file type and intercepts the call to the actual supporting application to resolve relation properties accordingly. In the document referencing use case, some note might reference page 42 in the PDF document my-paper.pdf. Tracker detects the reference relation and resolves its target through the SEN API. The relation is either resolved via context menu (“Open related…” → RelationType → Targets) or through the Tracker relation targets window (as seen above).
A Note on Relation Views and Folders
At first glance, it may seem quite a stretch to show relations as files in a separate “folder”, but if you think about the actual concept of a folder, it seems more consistent and intuitive:
Traditional folders also model a relation - a very simple one that is commonly misunderstood and consequently misused, causing all the trouble involved like duplicate files, crowded folders and the symptomatic “cure” of desktop search clients, nowadays even AI enhanced…
Folders model a Parent→Child relationship. This is true from the desktop UI down to the technical level, where you navigate to the pseudo directory .. to reach the parent directory. This was a simple and elegant solution that worked just fine when we had diskettes with 1.7Mb or hard drives below 4Gb and not many files lying around (even then it was already getting confusing).
With the arrival of cheap hard drives (and now even SSDs) in Tb sizes, this concept began to show cracks. Users tried to “organize” their files into folders, but that honorable effort was soon doomed because it breaks the original semantics of a Parent→Child relation that folder still hold. What users actually want to do is Categorization and Labelling, not technically moving files under a specific directory.
This creates all the issues we see in current desktop usage, and the time has come to end this misery, because even the best desktop search or AI assistant is not a cure-all for bad organization and design deficiencies of the underlying system.
With SEN, you can have truly dynamic classification and organisation in virtual “folders”, which contain relation targets for a specific source. This in addition to the already powerful file system based fast Queries available in Haiku by default - which act the same way and are used for showing new mail messages (also file based), contacts with specific properties, or other user defined reports. SEN transparently blends in and just adds some semantic spice to the already powerful desktop environment.
As a more advanced feature, SEN also supports self relations (pointing back into the source, like a “Contains” relationship). Here you can see PDF bookmarks being extracted dynamically in realtime and shown as contained relations that can be viewed and navigated just like other relations:

Now the file system really becomes a database, or rather a knowledge graph, and the UI consequently acts as a dynamic query tool and information space. Relation views and Query results are just like database results, and persistent Queries act like database Views.
Using Relations
Users just invoke relations like any other file, and Tracker resolves the default application for that relation via the standard OS file system API. The DocumentReference handler receives the actual target document, invokes the document’s default viewer and - through some integration code, preferably native Haiku messaging - jumps to the referenced page by inspecting the relation properties provided in the relations attributes.
This was way too much detail for a yearly review, but I didn’t want to make you wait longer for this corner stone of SEN’s technical design, and you read too many standard yearlies already:)
Once this blocker (in my mind) was removed, I could continue with the broader topic of how to configure entities (like Books, Movies or Papers) and their relations.
Ontologies in the Filesystem
An integral part of any linked data / knowledge management system - and even more for a semantic infrastructure like SEN which is integrated with native file types and the file system - is on how to set up a consistent way to handle entity and relation definitions.
I have thought long and hard about how to strike a balance between a simple, easy to use system that is still true to semantic principles like consistency and well formedness but can still be configured and extended flexibly so users can tune it to their needs.
The solution was again in using already existing native tools and formats, in the case of Haiku, Resource definitions, which are text based and easy to write and version, and which can be converted to native file types via the system tool rc, a native resource compiler.
Resulting resources can be converted to file type meta definitions (again using custom metadata storec in filesystem attributes), and installed as file types, which show up in the system’s FileTypes preferences and can be configured if so desired.
Now the only remaining issues were:
how to install file types from resource files without requiring a reboot
how to include plugins
how to keep track of installed entities and relations
For a short-time solution, I developed a shell script to keep track of installed entity and relation types by using the power of SEN relations and a custom Ontology file type. Eventually, ontologies will be packaged as native Haiku packages per entity and per relation, which allows me to use the existing infrastructure for dependency declaration and installation management.
The issue with having to reboot was solved by developing a little tool to access the MIME type API, so the file type can be installed directly. This will be integrated with the final solution later.
A bigger issue to deal with is on how to grow the system in a consistent and interchangable way, so that SEN ontologies can be exchanged and evolve without breaking stuff. Package management helps to clearly define dependencies (Relations need to define which Types and Attributes they support). But Attributes need to stay compatible and use standardized names and types. At the same time, users should be able to adapt the configuration in some way. Most of the time, they won’t need to and this is left to developers taking care of defining a consistent set of file types.
I intend to apply well established API design principles like backwards compatibility through never deleting or restricting properties and only add new ones. Since ontology packages are versioned by design, compatibility can be guaranteed by defining version dependencies between components. With some sane guidelines and common practices, developers can then easily build ontology packages and distribute them separately from SEN via standard Haiku software repositories.
Using the native package and software distribution infrastructure has the added benefit of keeping dependencies and complexity of SEN core minimal, while providing maximum flexibility to ontology designers. People are free to include AI libraries and models of different sizes for relation and entity extraction, for example.
First use cases
Since SEN is still hard to explain but easy to show - there is always this “a-ha”-effect when people see it in action, no matter how well you explain it in words - and also to validate my design decisions, I developed some use cases which I think would make SEN useful to interested people.
Book Notes
My personal favorite and one of the triggers to develop SEN in the first place (over 20 years ago, mind you) was to allow easy and consistent tracking of notes on books I have read, want to read or have read/heard about.
When you work with a data-centric desktop system like Haiku, it becomes natural wanting to manage your stuff as abstract files and define file types for your real world (or virtual) entities as you work with them in the digital world, like digital twins (but this has now become more of a manufacturing term).
Taking a step further with SEN, you can even define useful relations like Quotation, Authorship, Publishers or other notes on the same book, related work etc. You could even reference Topics, Projects or other categorization with SEN Meta handling coming soon.
A nice touch is that you don’t have to enter all the book metadata yourself, just an ISBN is enough and a suitable SEN plugin will do the Enrichment (one of the E’s in SENSEI mentioned above). For now, I did some prototyping with a simple Python script that takes an ISBN and looks up all the book metadata in a free online service, then creates a Book file with the book’s metadata stored in the file’s custom attributes, including the cover image, which is then used as icon - and voilà, you have a simple personal library management system!

You can use the standard system wide Find dialog to search for a book via ISBN, Title or Author:

Other use cases to follow in the next update…
SENity: a simple semantic notepad
From the beginning, a long time goal of this project was to build a universal notebook on top of SEN that shows the power of truly semantic filesystem powered linked object notes beyond Markdown links between text files (desktop wikis existed in the early 2000s already).
So in November, I have finally started to take an open source Markdown parser, put it into a customized TextView and add some magic. The result is SENity, an editor for your thoughts:)
This is not yet another plugin-ridden text editor with a browser inside (I don’t really like Electron and other web technologies for desktop apps that are supposed to be small and fast), but a fully native C++ hand crafted beast of an editor that loads and renders a usual Markdown text file in an instant.
The editor is also developed in the open but heavily work-in-progress (it does not yet support actually editing the text, for example, so it’s more of a viewer now, but all the underlying preparations are almost done and the editor understands the various parts of the markup. Here is a first look (highlights and annotations will be supported first):

A nice AI generated logo will soon be unleashed when the basic feature set is done:)
Milestones Achieved
So to wrap up 2024 finally, SEN has seen a lot of progress and love, including:
Tracker (file browser) integration
Semantic navigation (deep links) via plugins including self references
simple ontologies based on native FileTypes
book notes use case with a simple Library using enrichment and relations
a simple Markdown based text editor with semantic linking (highlights, soon entity links)
some PR: Presentation and Feedback, a fresh web site!
devs rejoice: fully open source all code on Github!
Short Outlook into 2025
As of tomorrow, I will tackle these:
funding (need your support!)
finish SEN core and Tracker integration
finish first preview of SENity editor
prepare a first tech preview (VM + live USB)
more use cases, including AI based entity extraction
documentation!
open source it all (core missing, rest is already built in the open)
already done! see SEN Labs@Github
That was much more than a recap but you deserved it - see you in 2025 and please support my work as you can! Prosit Neujahr :=)
Thanks for the huge update! I'll check out your source code on GitHub.